
The Bargain Bin Bielsa Machine
Giving coaches the interactive-web-app treatment
News in brief: I’ve updated the coaching clusters model to look at individual matches, discovered FBRef’s advanced data coverage also includes the WSL and MLS, and gathered it all into an interactive web app.

Back in August, I unveiled a player scouting tool I’d made. Courtesy of some incredibly kind tweets from John Muller, Ryan O’Hanlon and Tom Worville, the accompanying article (/newsletter/whatever this is) quickly became, by some distance, my most-read piece of work since a blog post I wrote about the Oyston family was kicked around a Blackpool forum for a day or two in early 2019.
Buoyed by the generous praise, I naturally took this as my cue to embark on a lengthy hibernation. It wasn’t my intention to go silent, but there we are.
I’ve been keeping busy though. Over the last three months I have: started several projects; travelled down to Stamford Bridge to lurk in the shadows at the StatsBomb conference; been to see real life football for the first time since the pandemic; and then terminated several projects, owing either to lack of legs, being mathematically impossible, or because it gradually became apparent that any chance of succeeding in my aims fundamentally hinged on predicting the future to an extent that, were I to manage it, would make me incredibly, incredibly rich.
So, like a Scandinavian coach arriving at a club in mid-season turmoil, I’ve decided to go back to basics. One day soon I’ll take a break from the words “clustering algorithm” and “dimension reduction”, but before I do, I figured I may as well pluck the remaining morsels of meat off the bones and give my coach-clustering project a juicy upgrade.
It’s called, of course, The Bargain Bin Bielsa Machine.
The general gist of what’s going on here is largely the same, so I’d highly encourage you to read up on my original attempt at this if you want to better understand the process. But very briefly, I told a computer to read through a load of data, spit out a set of x and y coordinates, and try its best to divide the resulting graph into 8 distinct sections which we’ll call playing style clusters. Here they are, in heatmap form:
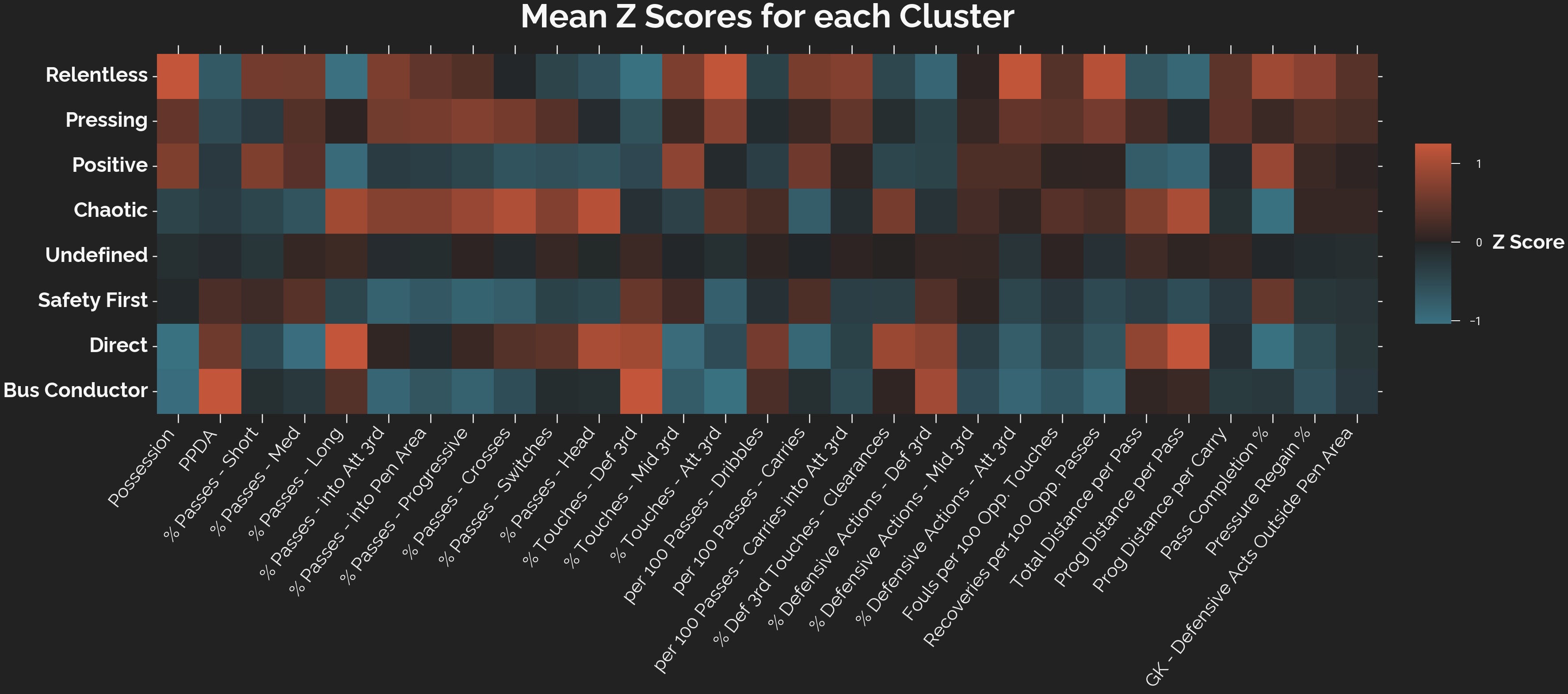
And the map:

Many familiar faces, there. But that map has grown a hell of a lot bigger since last time you saw it. Here’s why:
Update #1 - “They play football over there???”
I have visited fbref.com hundreds of times over the past year. And yet, until very recently, I had absolutely no idea that they provided ‘advanced’ metrics for leagues beyond Europe’s big five. So, in case anyone was wondering, I can now assure you that it was not a conscious decision to exclude the Women’s Super League and MLS from my previous work. They have now joined the party.
Update #2 - Getting Granular
Early on in the original process, I took the decision to look at coaches on a club-by-club, season-by-season basis. I felt that breaking down Jose Mourinho, say, into bitesize chunks and treating his time at Manchester United as a separate entity to his Spurs days (and so too for each of his two seasons in Tottenham, etc.) gave us a more meaningful insight than just lumping together all his data across four years and two different clubs and taking one nice, simple average - a coach could change style drastically when thrown into a new environment with totally different players, and that should surely be taken into account when trying to capture the true, unfiltered essence of Mourinho.

But why stop there? It’s all well and good declaring Brendan Rodgers’ 19/20 Leicester were a ‘Relentless’ side, but did they always play like that? How much did their style vary from week to week? Or from the first 19 games to the second? Was there a redemption arc? What’s the narrative???
This time, then, we’re plugging each individual match into the supercomputer, meaning our map has increased from ~450 data points to almost 20,000. And it also sees us wave goodbye to the neat and tidy ‘coach x in season y belongs to cluster z’ model.
Update #3 - I am 39% certain that Steve Bruce is a bus conductor
If you’re not the slightest bit familiar with data science, please forgive the upcoming jargon. It’ll be over soon.
First time round, I used k-means clustering to define 8 different styles of play. When I moved on to look at players, though, I switched to a Gaussian Mixture Model (GMM), and that’s what I’ve done again. A key benefit to the GMM method is that it comes along with a ready-made function to not only assign each data-point to a cluster, but also tell you how confident it is in its decision, meaning we can treat points (i.e. matches, in our case) close to the border with another cluster with the flexibility they deserve.
What this allows us to do in practice is, rather than attach one definitive cluster to each coach, represent their overall playing style as a series of probabilities: for each game in the data set, we get eight scores indicating the likelihood that said game belongs to each of the eight clusters, and taking an average of those scores for each coach hopefully paints a more accurate, well-rounded picture of what they’re actually doing.

What I’ve found interesting about this is that, aside from those who’ve only taken charge of a handful of games and some notable other exceptions (e.g. Thomas Tuchel and Maurizio Sarri’s toxic positivity, or agents of chaos José Bordalás and José Luis Mendilibar), it’s rare that a coach scores above a 50% likelihood for membership of any of the clusters. Again, though it makes things a fair bit murkier, it does feel like a better reflection of reality.
Update #4 - Killing off the counter-attack
In the middle of the map is an oasis which I previously described as the counter-attacking cluster. This time, I’ve come to think of it as something of a watering hole where all the creatures of the savannah converge and put aside their differences for a little while. This middle cluster is just a rough mix of everything surrounding it, and has absolutely no defining features, so I’ve called it ‘Undefined’. I will accept suggestions for a better name, though.
Update #5 - Similarity ratings
The centrepiece of my last project was the similar player-finder, and now you can discover some coaching doppelgängers too. Similarity ratings are scored thusly: first, by measuring the distance between each and every data point on the graph, totting that all up and finding the average distance between each of a coach’s games and each of a given peer’s; second, by calculating the difference between each coach’s average cluster-probability scores; and third, transposing each of those two calculations on to a 0-100 scale, taking a weighted average (75% map distance, 25% cluster-probabilities), and then once again scaling the results to a 0-100 range.

It’ll do for now, but I might end up revisiting this in the future as there’s a few little things that are nagging me about it. Namely, that each coach has a counterpart rated as 100 on the similarity scale, when the truth is that the distance between a coach and their nearest neighbour can vary fairly significantly across the data set - one person’s 100 isn’t the same as another’s, and it’d be nice to reflect that better. Fixing this would involve scrapping the neat 0-100 scale, though, which would mean the scores are harder to interpret, but I’m sure there’s a satisfactory solution somewhere.
And that’s that. I intend to merge the two sites into one web-page, but the code for my previous effort, though it all works as intended, is incredibly messy in parts, making the clean-up process quite a daunting task. Before I get lost down that rabbit hole, though, I’ve made a commitment to myself to write more regularly on little bits and pieces, rather than solely setting myself grand, sweeping projects that take weeks or months to piece together, so I’ll be back again before you know it.